- Resources
- Data Parallel
- Deepspeed ZeRO Data Parallel
- Pipeline Parallel (Model Parallel)
- Tensor Parallel
- 2D & 3D Parallelism
Resources
- https://hanlab.mit.edu/courses/2023-fall-65940 lectures 17,18.
- Fully Sharded Data Parallel (huggingface.co)
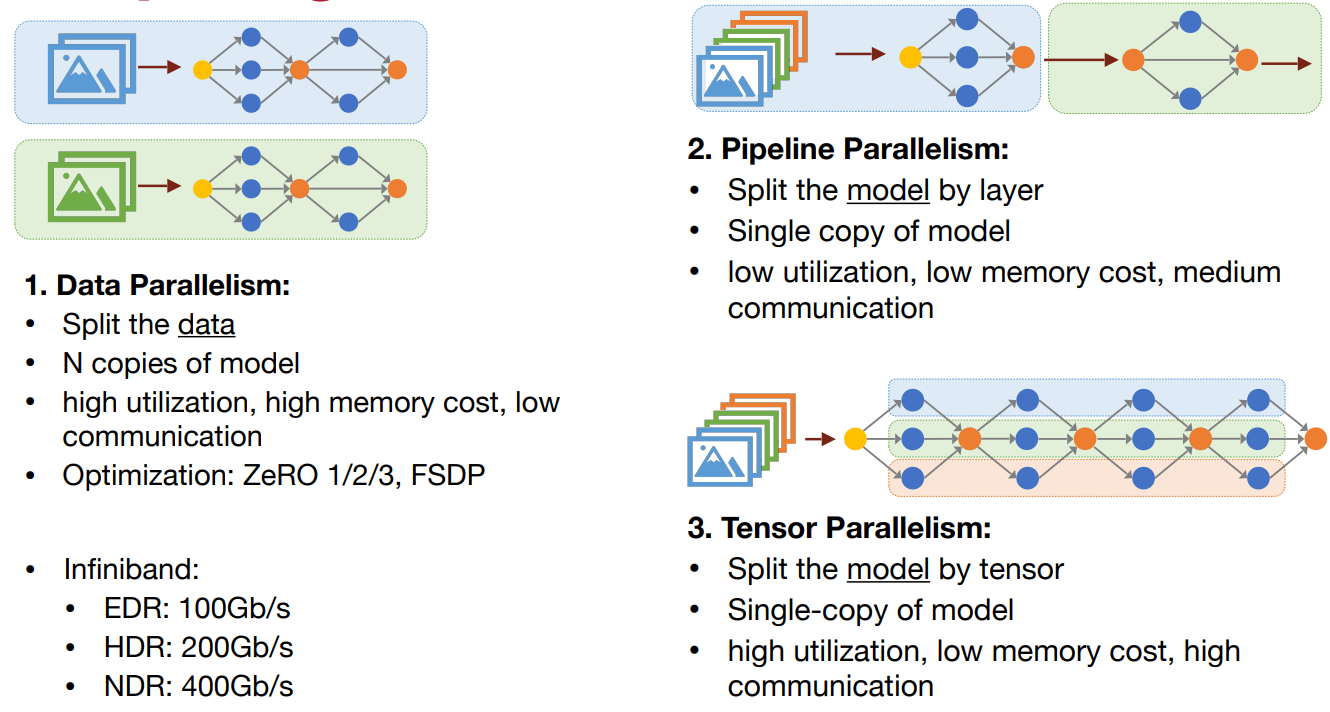
Types of distributed training:
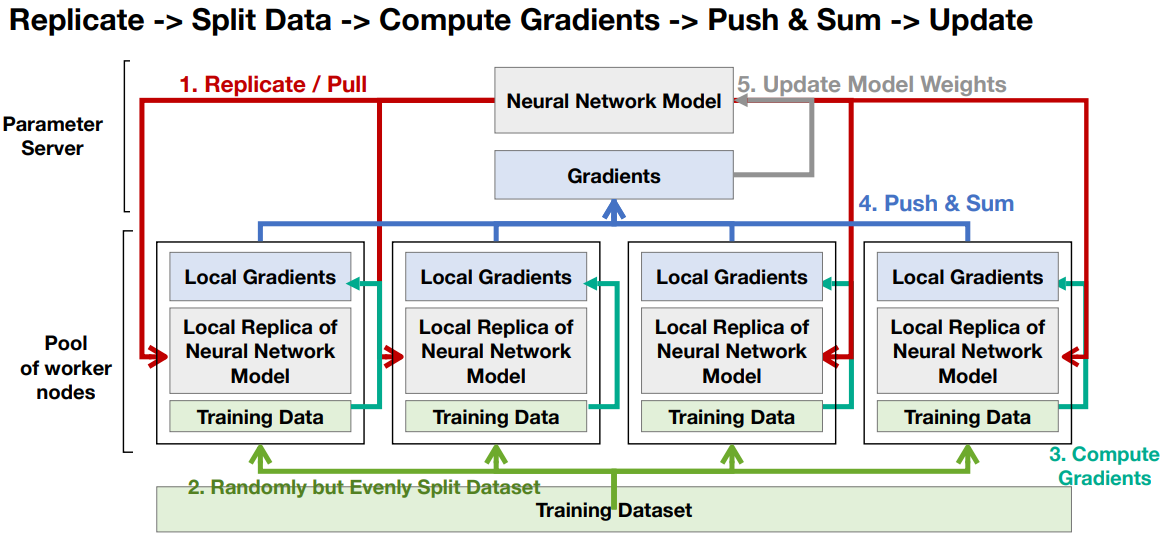
- Data Parallel:: Replicate model across gpu and distribute data across each gpu.
- DP, DDP: User if model fits in single gpu
- Deepspeed ZeRO Data Parallel::
- Zero - 1, 2, 3(=FSDP in pytorch)
- Pipeline Parallel (Model Parallel):
- Tensor Parallel:
- 2D & 3D Parallelism:
Data Parallel
| Feature | DataParallel (DP) | DistributedDataParallel (DDP) |
|---|---|---|
| Process Model | Single process, multiple threads | Multiple processes, each handling one or more GPUs |
| Model Replication | Replicated on each GPU at each forward pass | Replicated once per process |
| Input Data Handling | Splits input data across GPUs | Splits input data across processes |
| Gradient Aggregation | Gradients averaged on the CPU/Single GPU | Gradients synchronized across processes using NCCL |
| Performance | Better for smaller models. | More efficient, better scaling across multiple GPUs and nodes. |
| Scalability | Best for single-node, multi-GPU setups | Scales well across multiple nodes and GPUs |
| Synchronization | Implicit, handled by the framework | Explicit, requires setting up distributed process groups |
| Code Example | model = nn.DataParallel(model).cuda() | dist.init_process_group(backend='nccl'); model = DDP(model, device_ids=[local_rank]) |
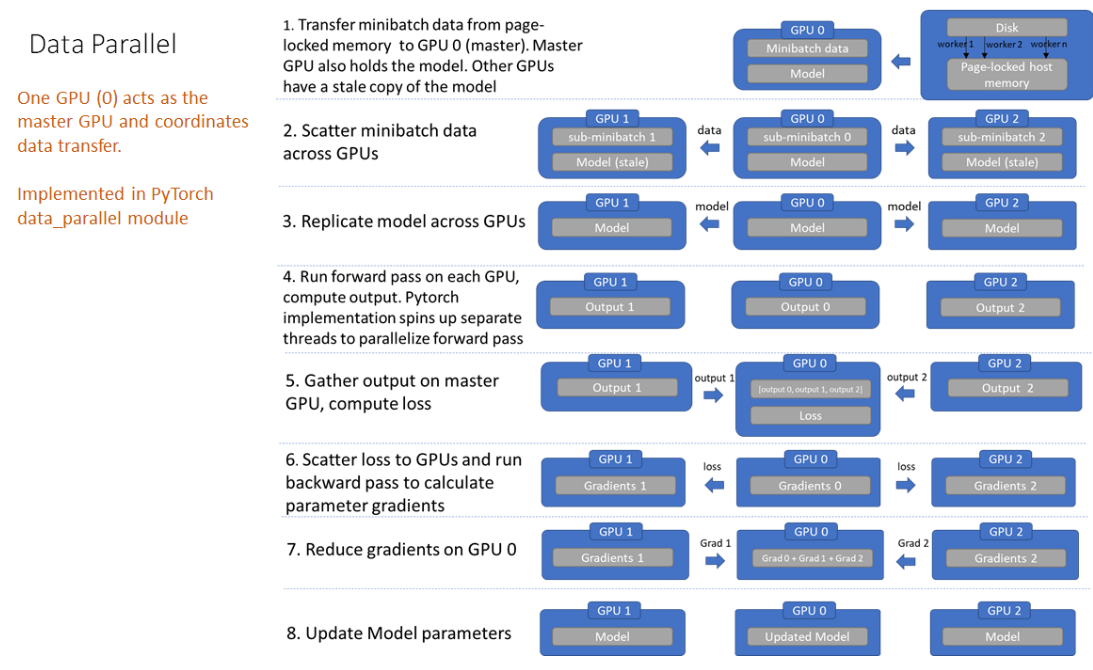
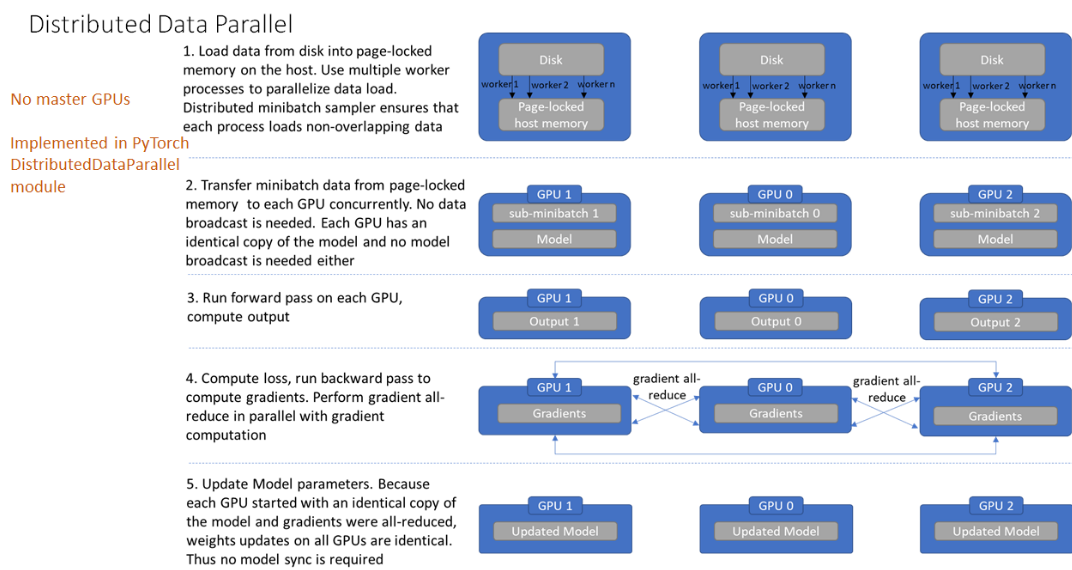
Conclusion:
- The only communication DDP performs per batch is sending gradients, whereas DP does 5 different data exchanges per batch.
- Under DP gpu 0 performs a lot more work than the rest of the gpus, thus resulting in under-utilization of gpus.
By default pytorch recommends DDP over DP, even for single node, multi gpu setup due to python GIL restrictions over multi threading.
Deepspeed ZeRO Data Parallel
Core deep learning algorithm involves three components for any model apart from inputs:
- Parameters
- Gradient
- Optimizer state Thus Deepspeed zero is divided into three stages:
- Stage 1 - Optimizer State Partitioning (Pos), sharding optimizer states across gpus.
- Stage 2 - Add Gradient Partitioning (Pos+g), sharding Gradients across gpus.
- Stage 3 - Add Parameter Partitioning (Pos+g+p), sharding Parameters across gpus.

Speed vs Memory:
- speed - Zero 1 > Zero 2 > Zero 3
- Memory usage - Zero 1 > Zero 2 > Zero 3
- Communication Overhead - Zero 3 > Zero 2 > Zero 1
- Bandwidth requirement - Zero 3 > Zero 2 > Zero 1
Pipeline Parallel (Model Parallel)
Splits the model across gpus, useful if model size larger than single gpu memory.
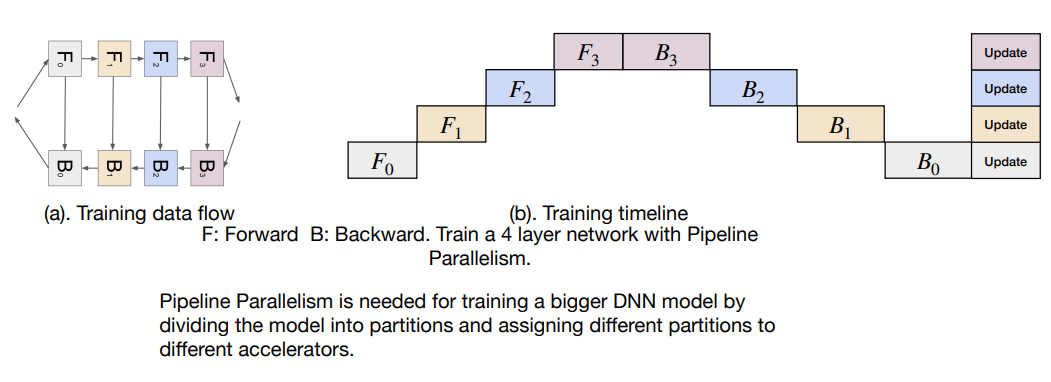
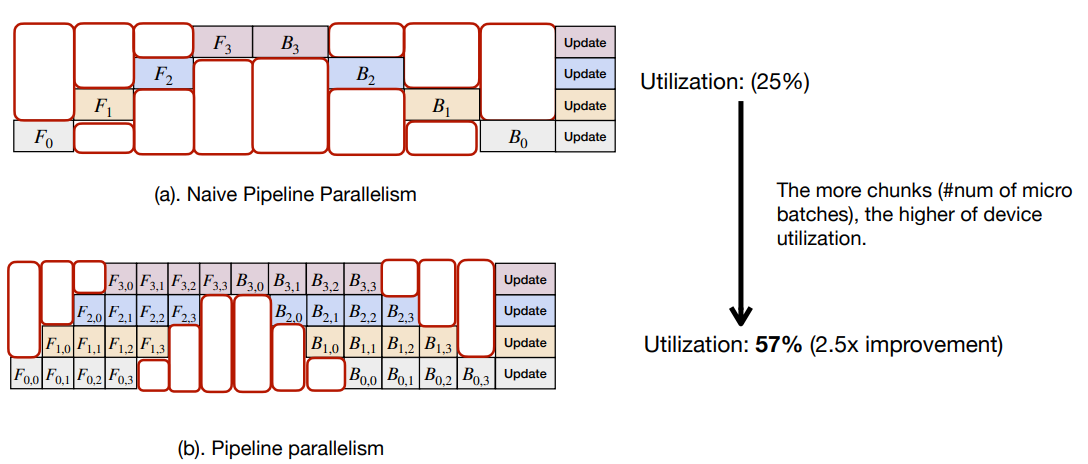
- Good for loading very large models
- Higher GPU idle time, it can be reduced using micro batches as shown above, still GPU utilization is poor compared to other techniques.
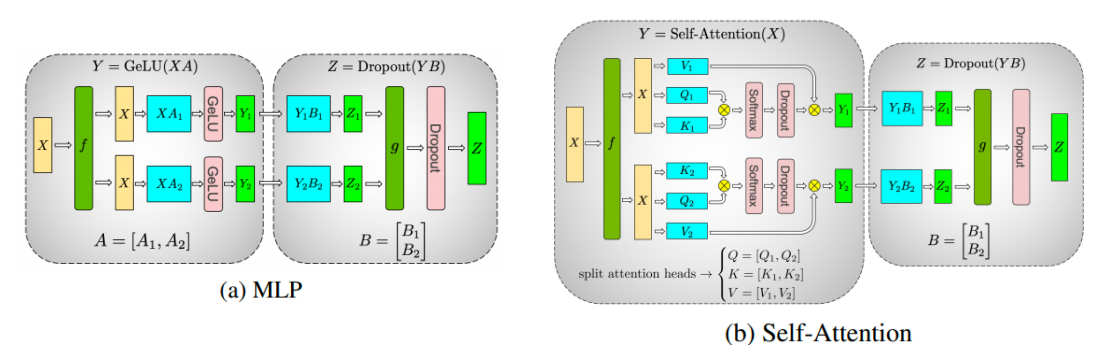
Tensor Parallel
Split a weight tensor into N chunks, parallelize computation and aggregate results via all reduce.
2D & 3D Parallelism
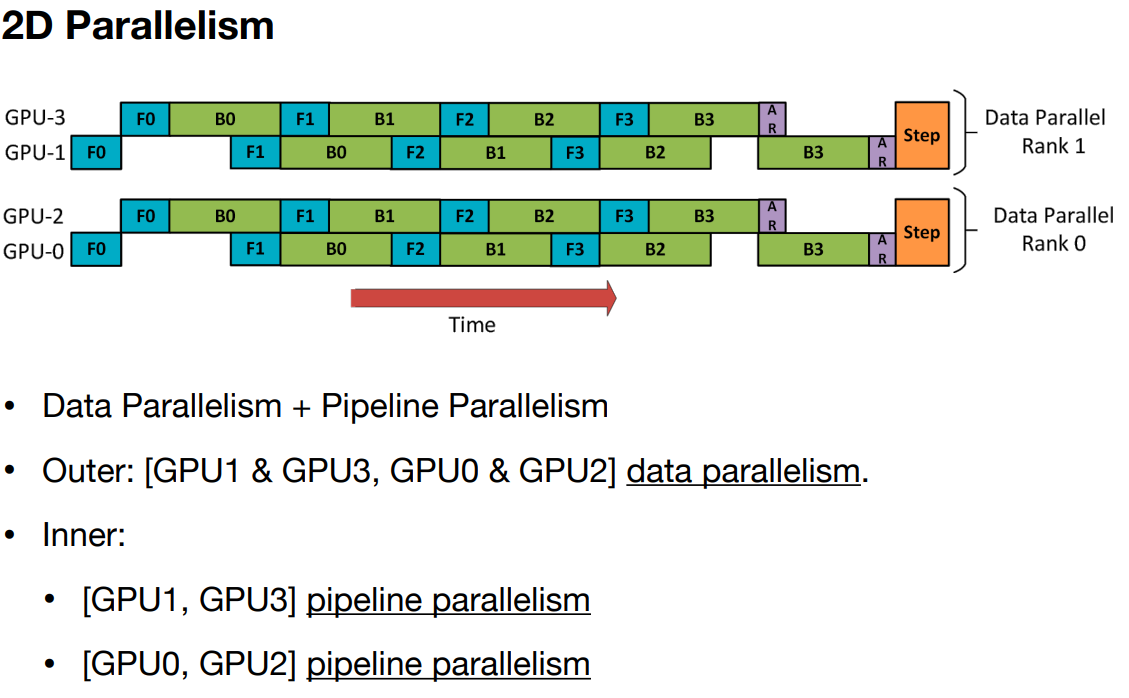
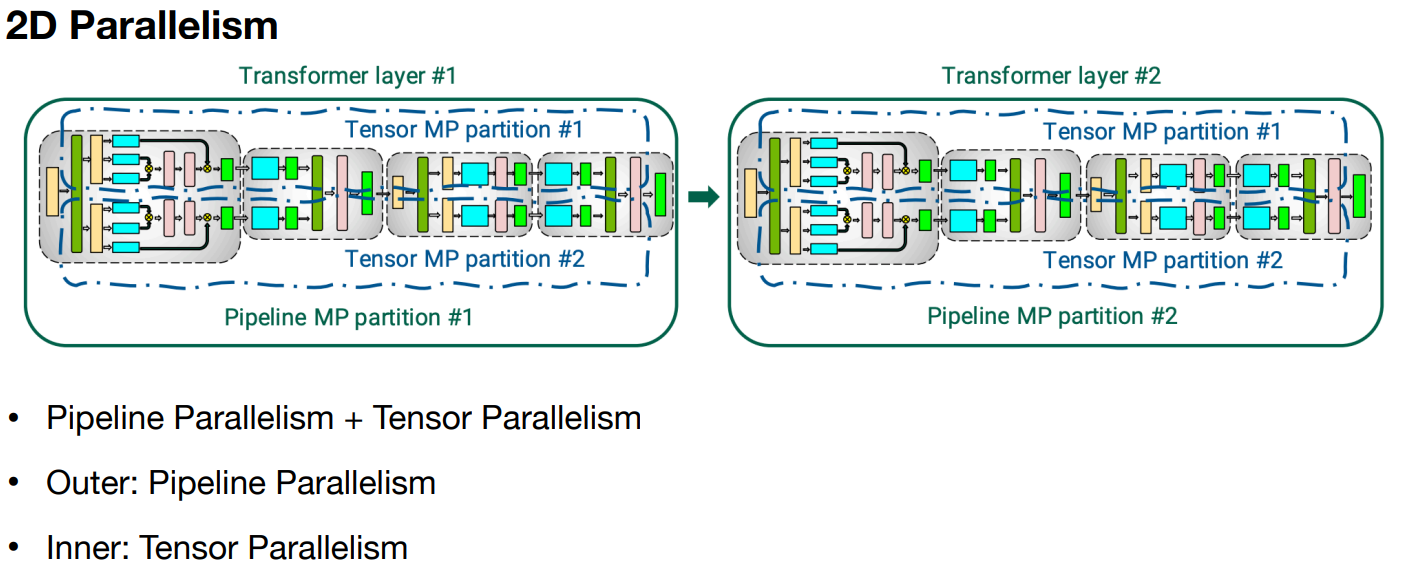
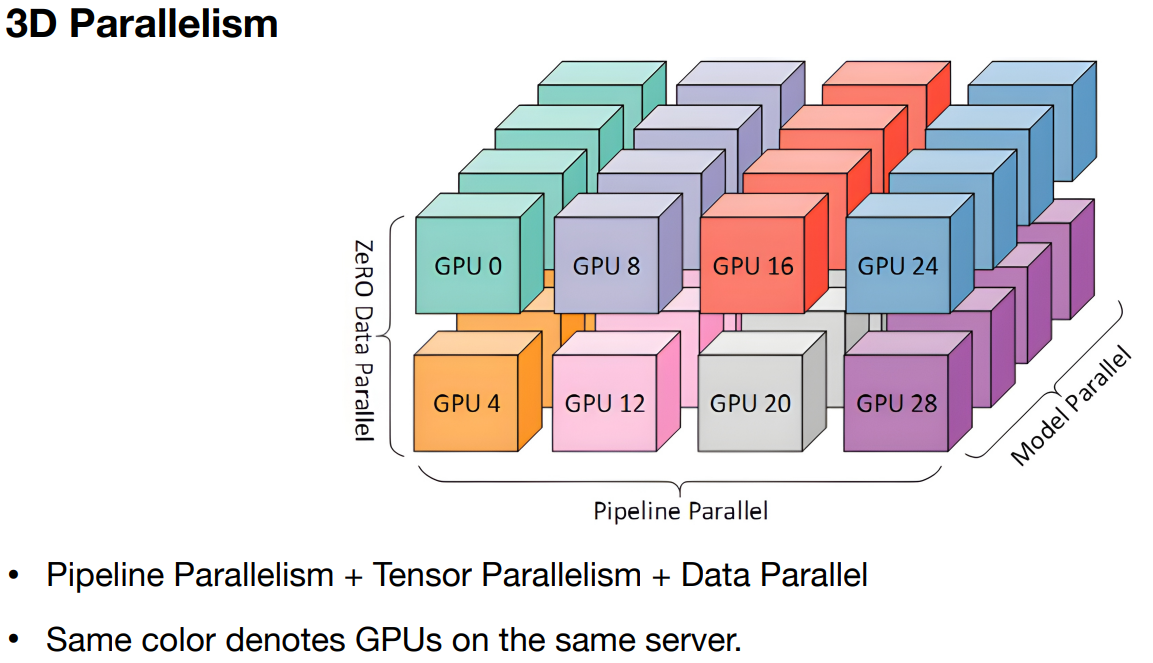
There are libraries which support 3D parallelism out of the box, below are a few.
- Deepspeed
- Nvidia Nemo.