-
| [[#Introduction: |
Introduction:]] |
-
| [[#Pruning Criteria: |
Pruning Criteria:]] |
| - [[#Magnitude based: |
Magnitude based:]] |
| - [[#Scaling-based: |
Scaling-based:]] |
-
| [[#Automatic Pruning: |
Automatic Pruning:]] |
-
| [[#Iterative Pruning: |
Iterative Pruning:]] |
Introduction
- Pruning - Making weight/activations to zero such that specific hardware can make use of it.
- Pruning ratio - Percentage of weights/neurons to be pruned. 60% pruning implies 60% of total neurons are pruned.
- N:M Sparsity - In each contiguous M elements, N of them are pruned.
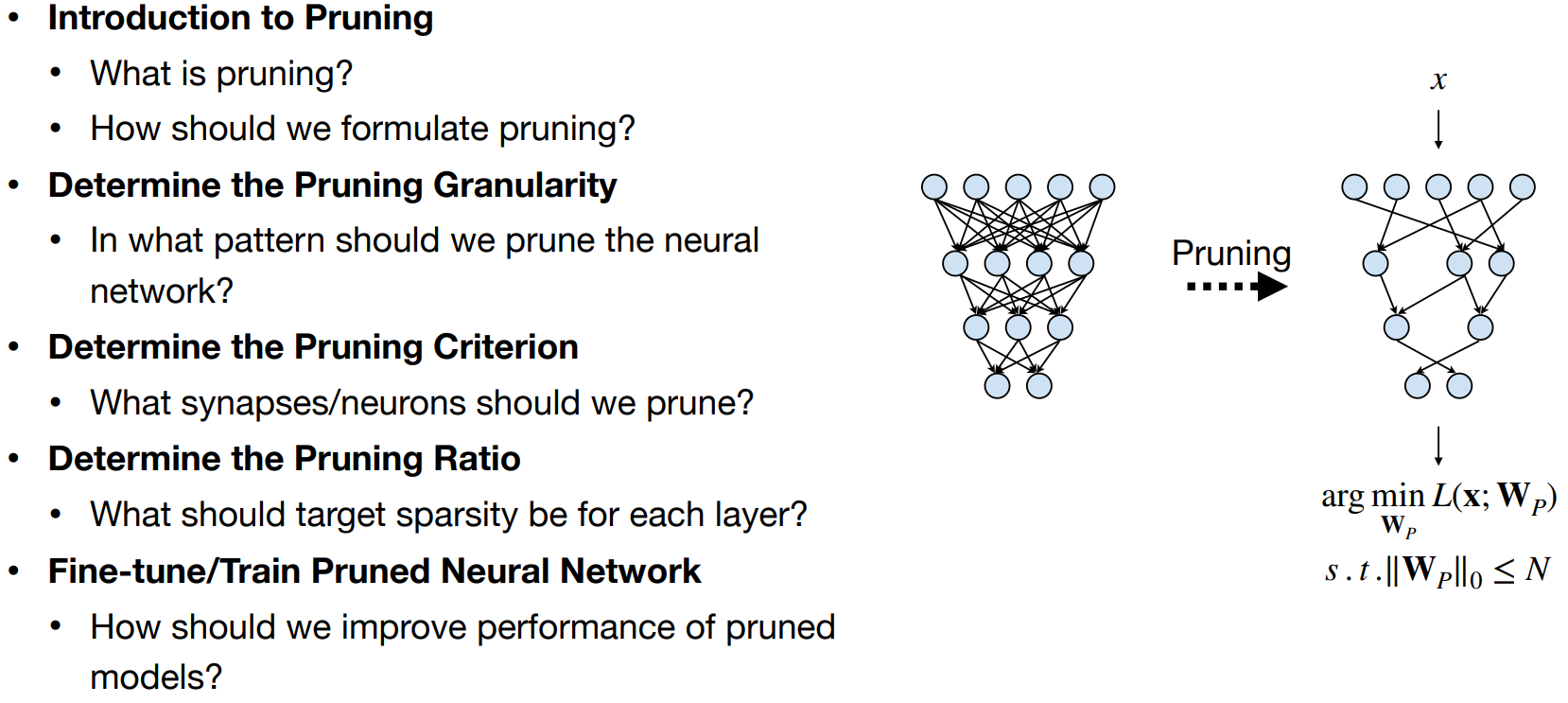
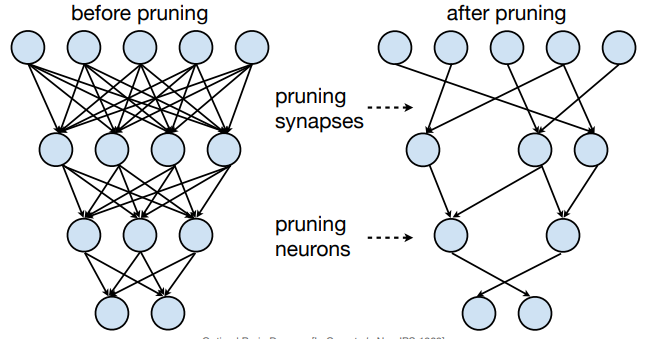
Two types of pruning:
- Synapses pruning
- Neuron pruning
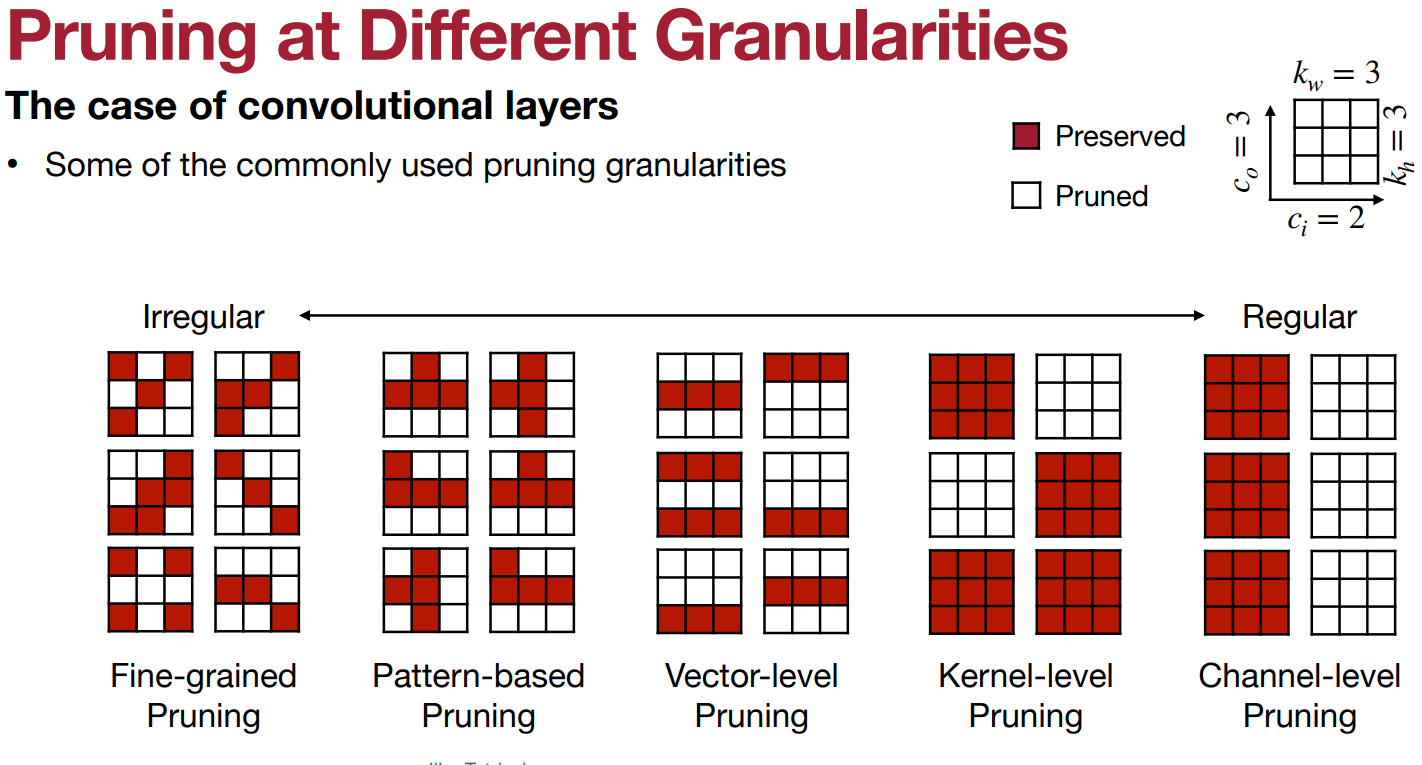
Fine grained Pruning:
- Flexible pruning indices
- Usually results in larger pruning ratios.
- Needs custom hardware.
Pattern-based pruning:
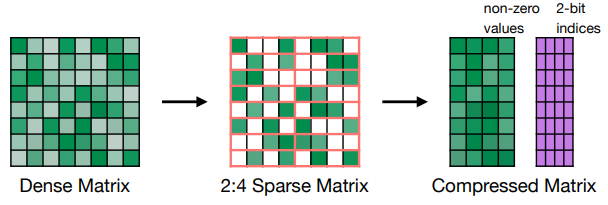
- N:M Sparsity, 2:4 sparsity (50% sparsity)
- supported from Ampere GPU architecture
- Maintains accuracy
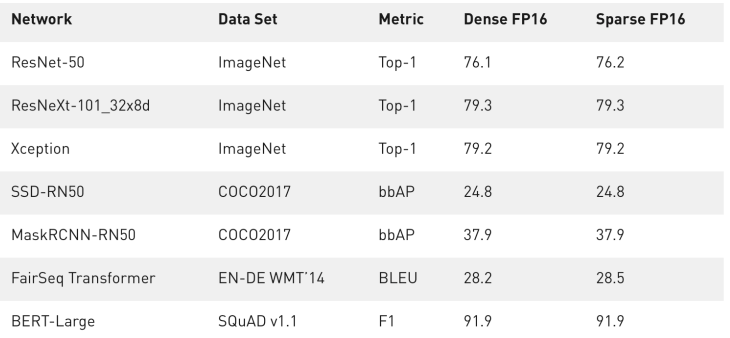
Channel Pruning:
- Smaller compression ratio
- Direct speed up due to reduced channels in NN.

Pruning Criteria
Magnitude based
- Element wise pruning using absolute magnitude threshold
- vector wise pruning using vector wise L1/L2/Lp norms
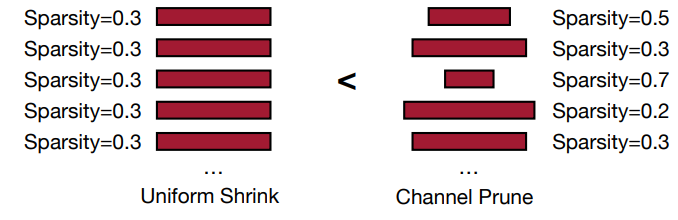
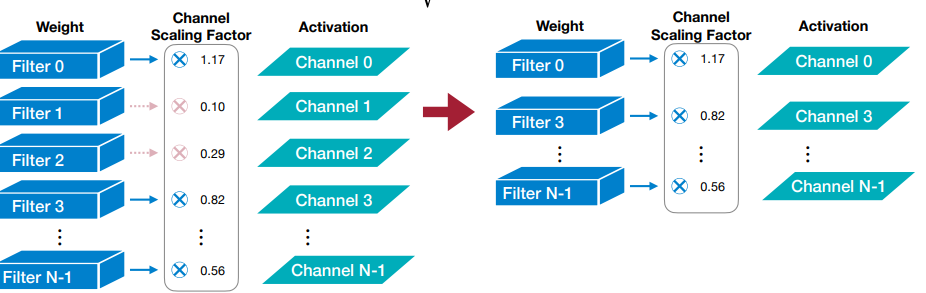
Scaling-based
- Used for channel (filter) pruning
- Trainable scaling factor is multiplied to each output channel and channels with small scaling factor are pruned.
- Scaling factors can be reused from Batch norm layers.
Automatic Pruning
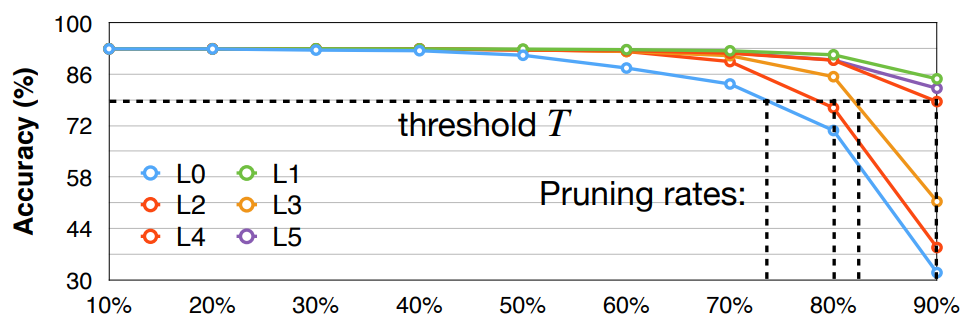
Layer wise pruning:
- Sensitivity analysis for per layer pruning ratio, by observing accuracy degrade with each pruning ratio.
AMC: Auto ML for model compression:
Iterative Pruning
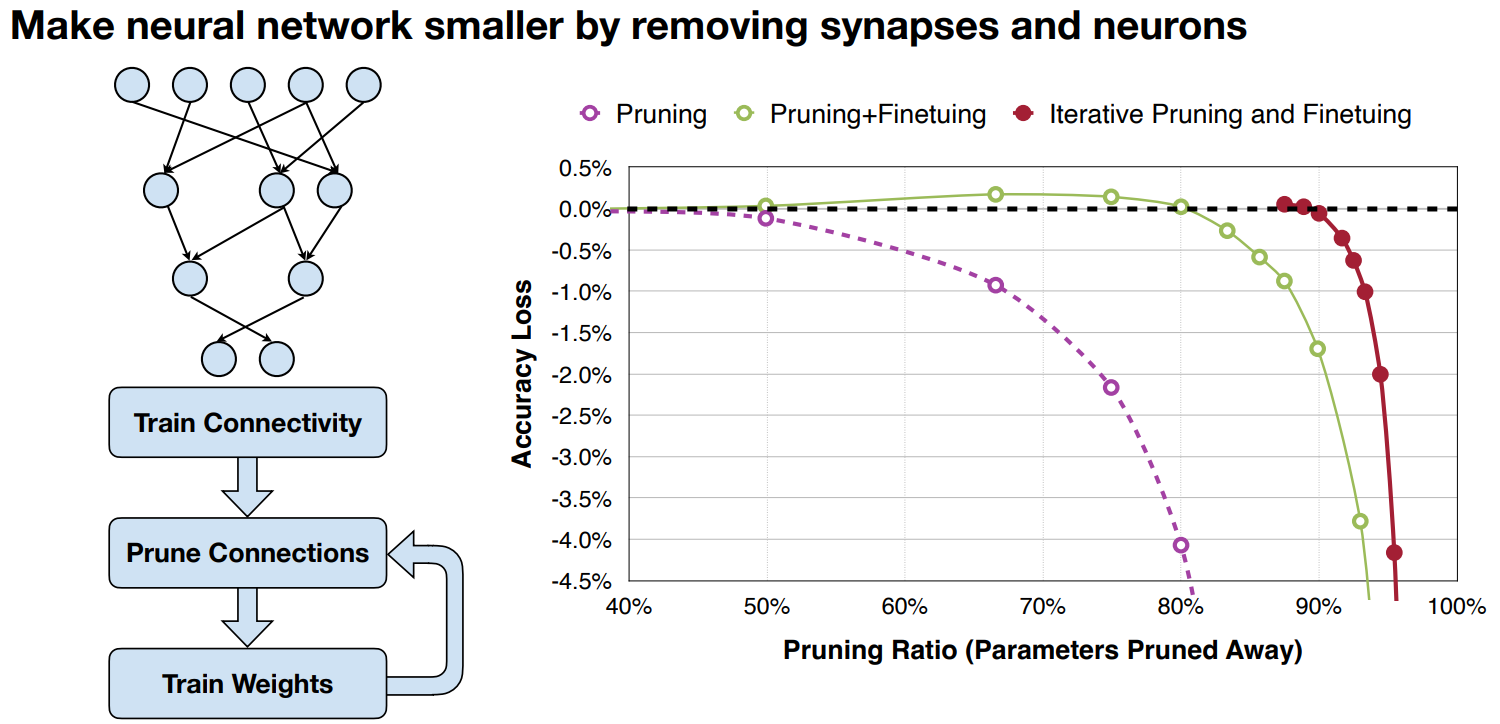
Iterative pruning:
- Prune pre trained model.
- finetune pruned model for 1-5 epochs.
- Iterate pruning and finetuning as required.