We use cookies on this site to enhance your user experience
By clicking the Accept button, you agree to us doing so. More info on our cookie policy
We use cookies on this site to enhance your user experience
By clicking the Accept button, you agree to us doing so. More info on our cookie policy
Usual Training process:
R1 Training process:
start from base model and follow below steps

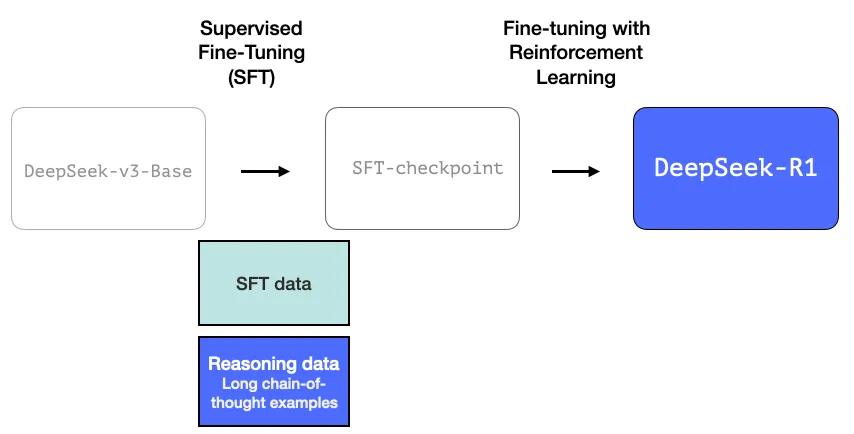
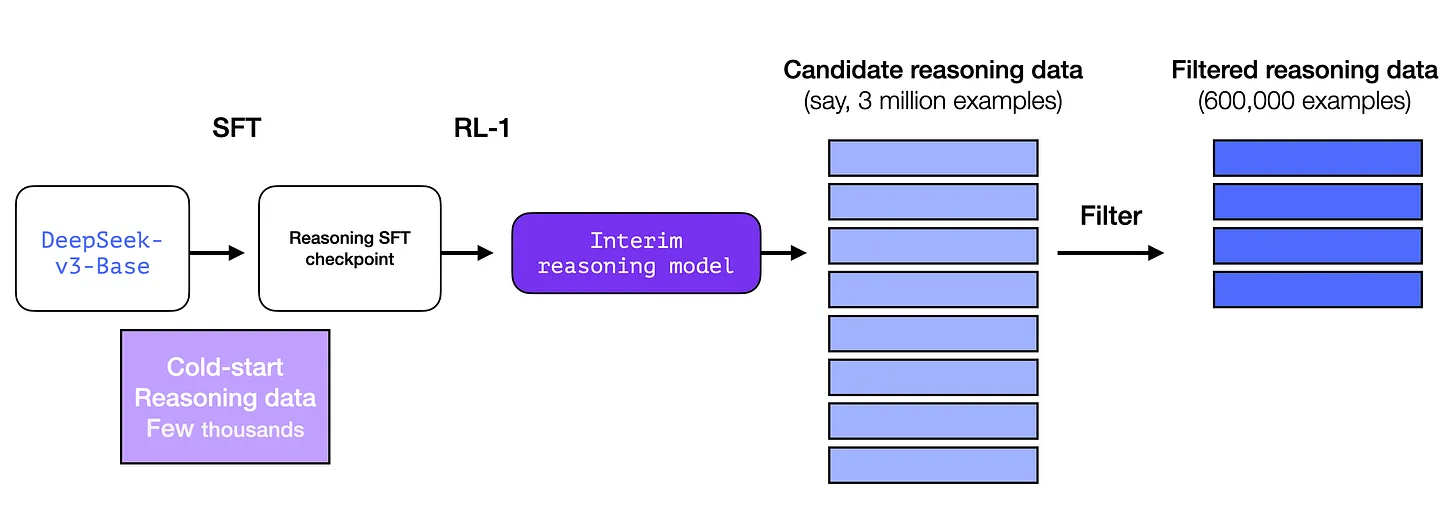
An interim high-quality reasoning LLM (but worse at non-reasoning tasks).
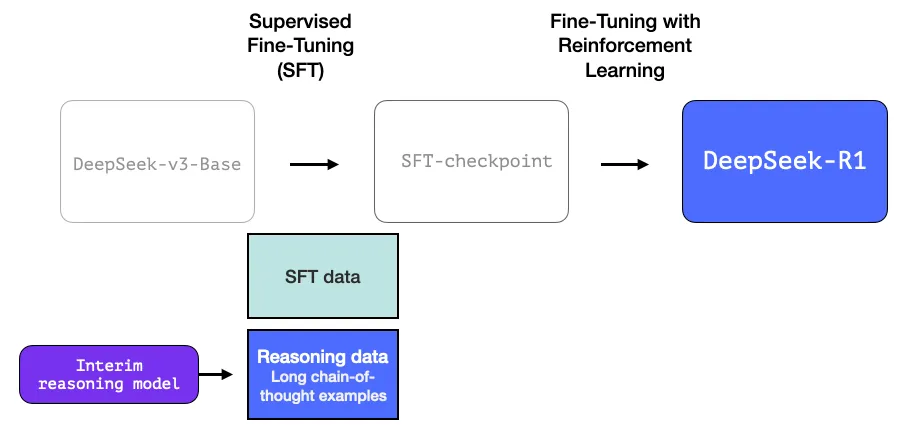
Creating reasoning models with large-scale reinforcement learning (RL)
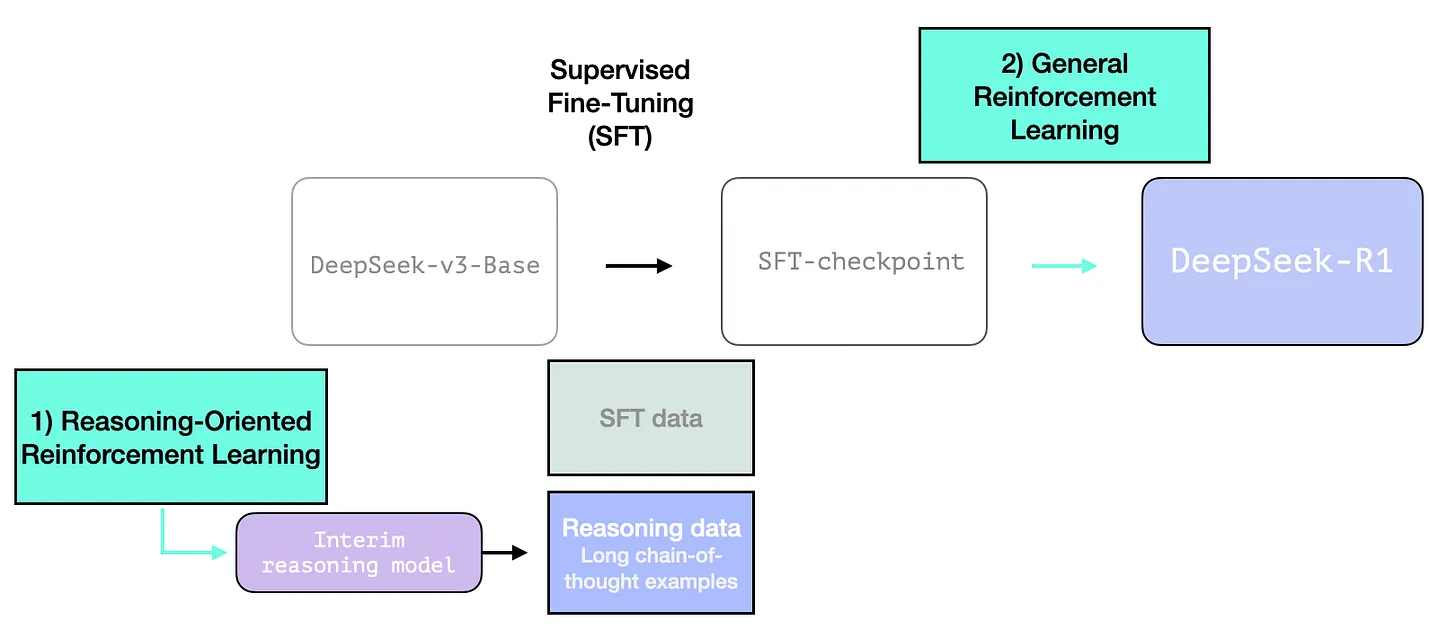
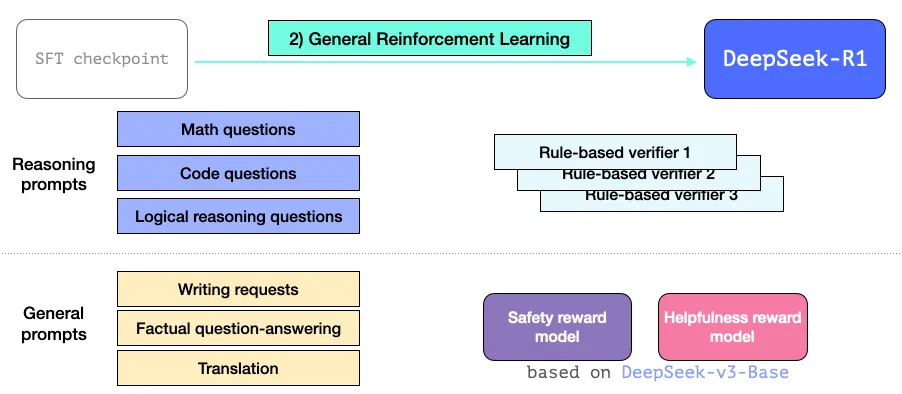
 Although DeepSeek-R1-Zero exhibits strong reasoning capabilities and autonomously develops unexpected and powerful reasoning behaviors, it faces several issues. For instance, DeepSeek-R1-Zero struggles with challenges like poor readability, and language mixing.
Although DeepSeek-R1-Zero exhibits strong reasoning capabilities and autonomously develops unexpected and powerful reasoning behaviors, it faces several issues. For instance, DeepSeek-R1-Zero struggles with challenges like poor readability, and language mixing.
It is used in two places:
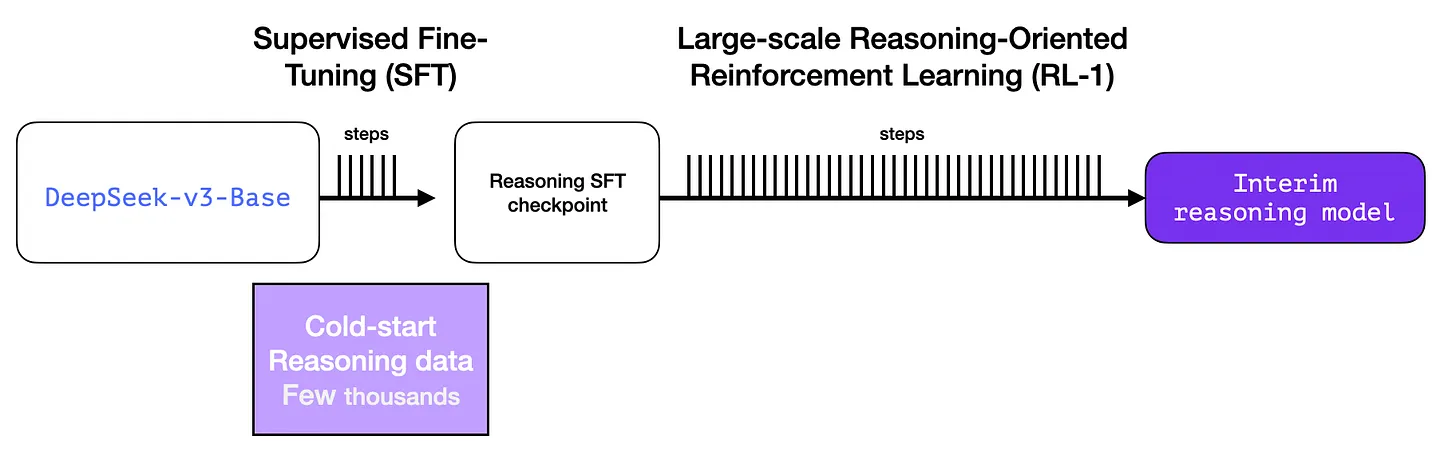
To prevent unstable cold start phase of RL training, CoT data is collected for SFT phase Cold Start CoT Data:

Latest Posts