We use cookies on this site to enhance your user experience
By clicking the Accept button, you agree to us doing so. More info on our cookie policy
We use cookies on this site to enhance your user experience
By clicking the Accept button, you agree to us doing so. More info on our cookie policy
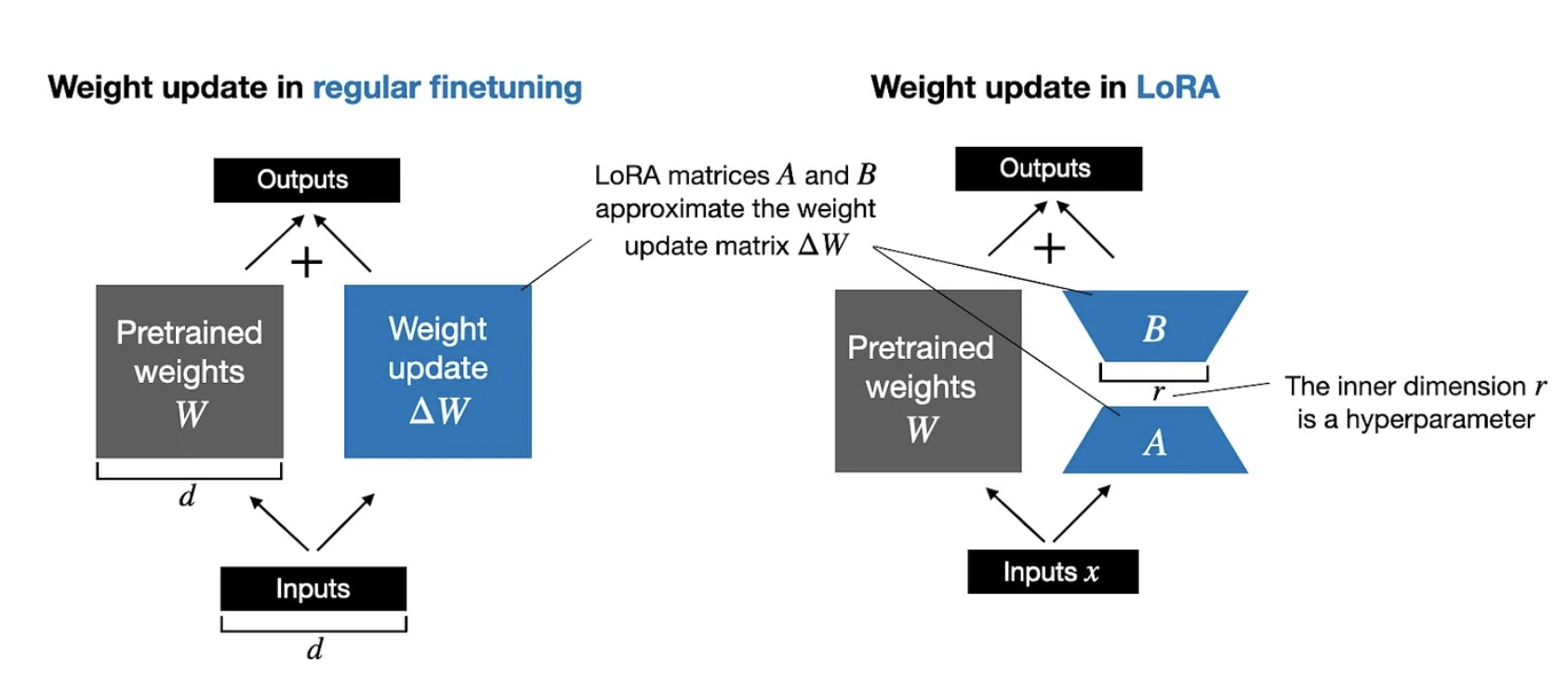
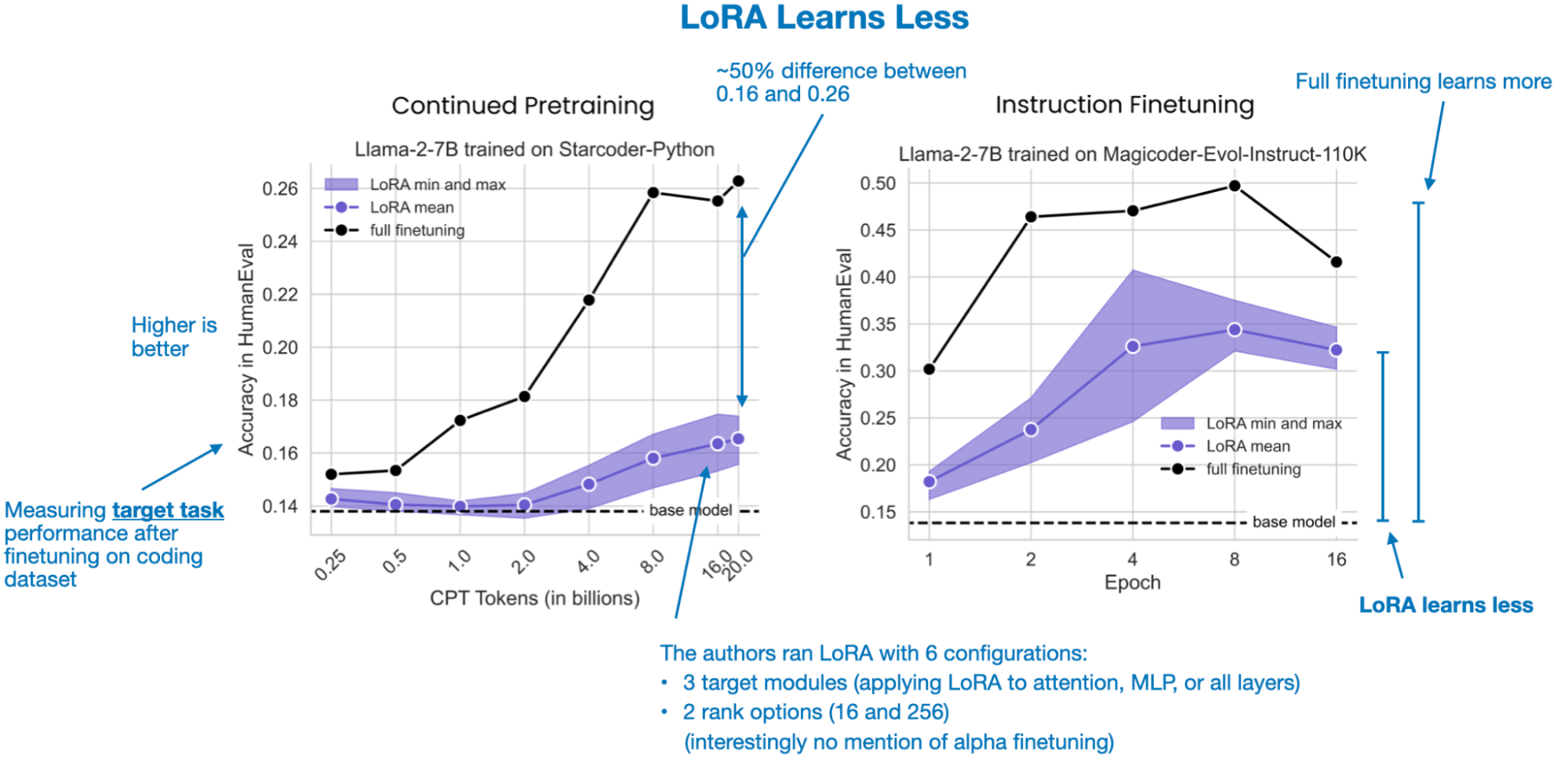
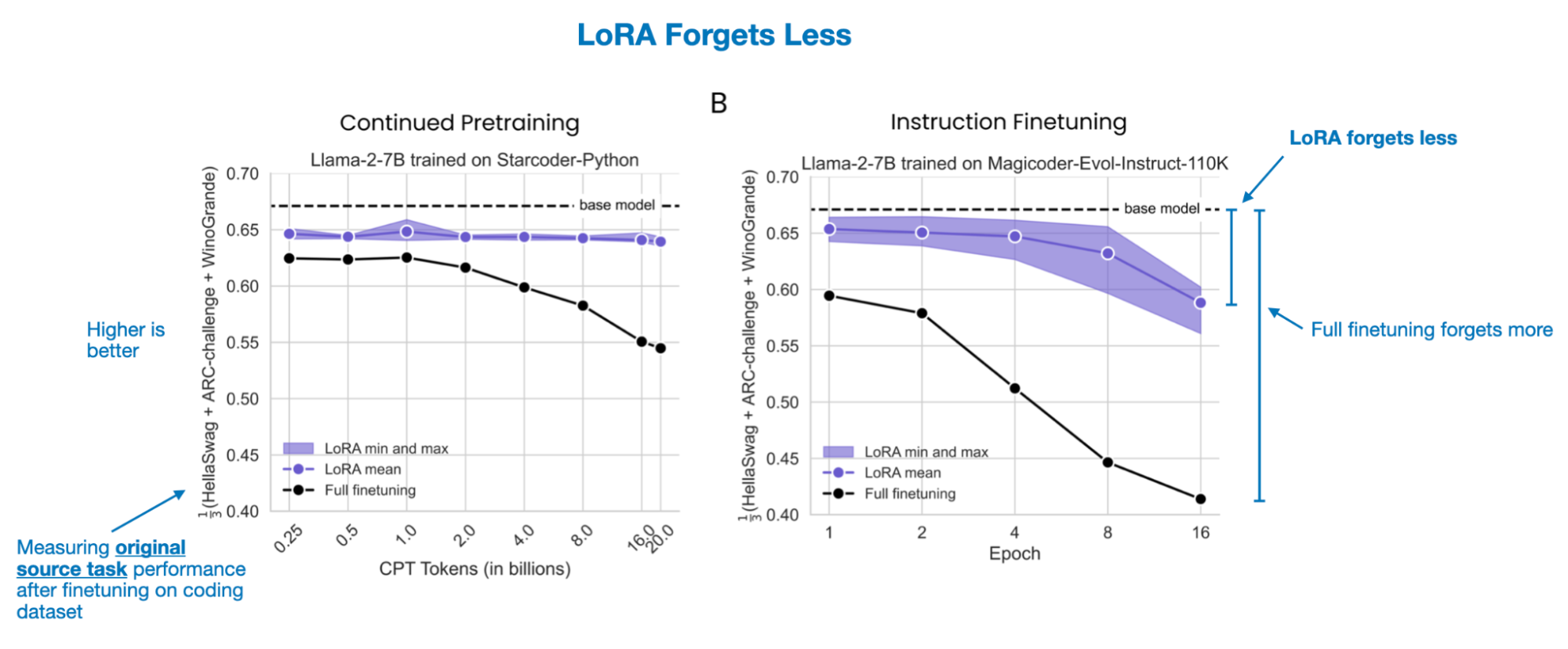
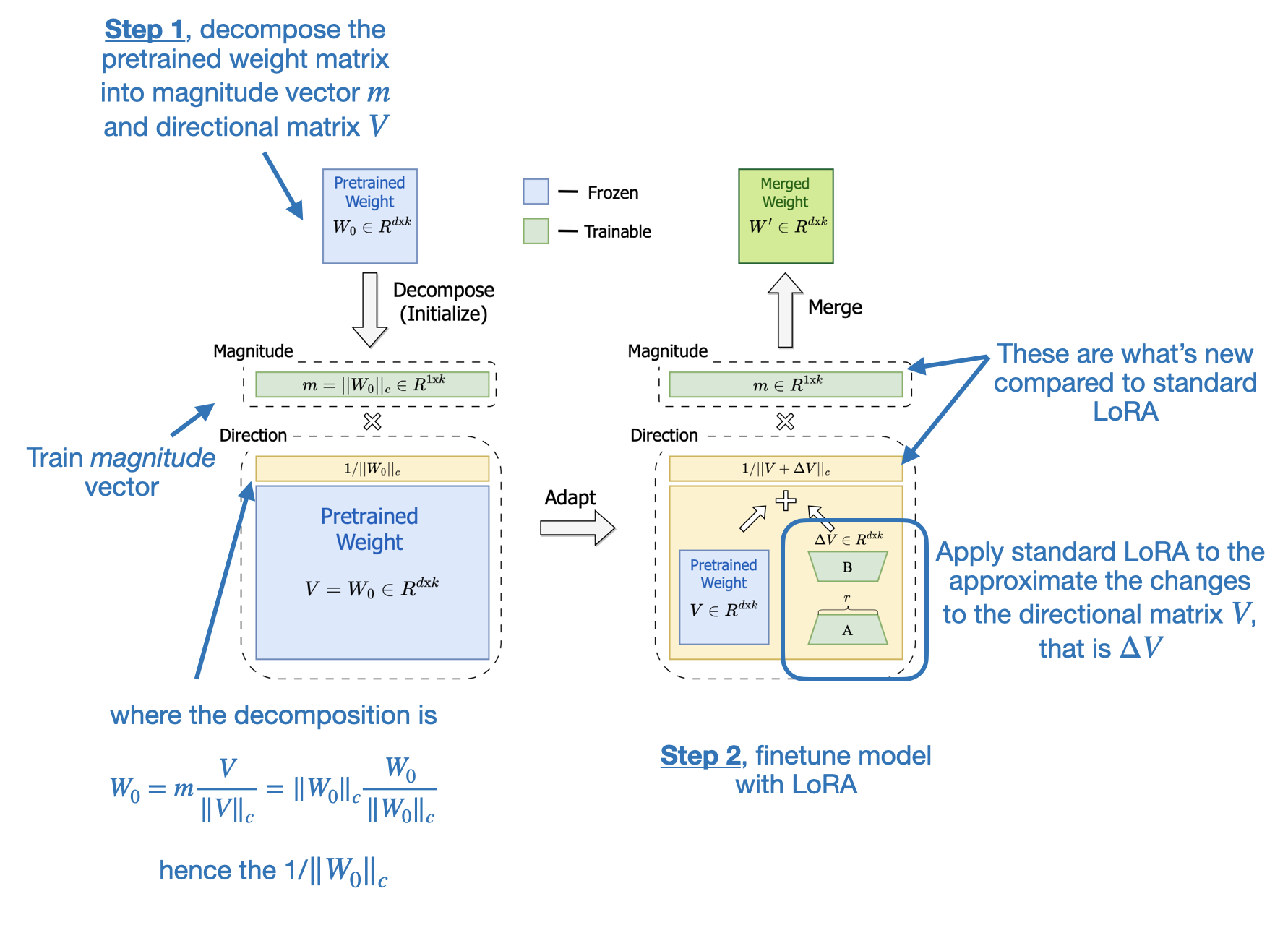
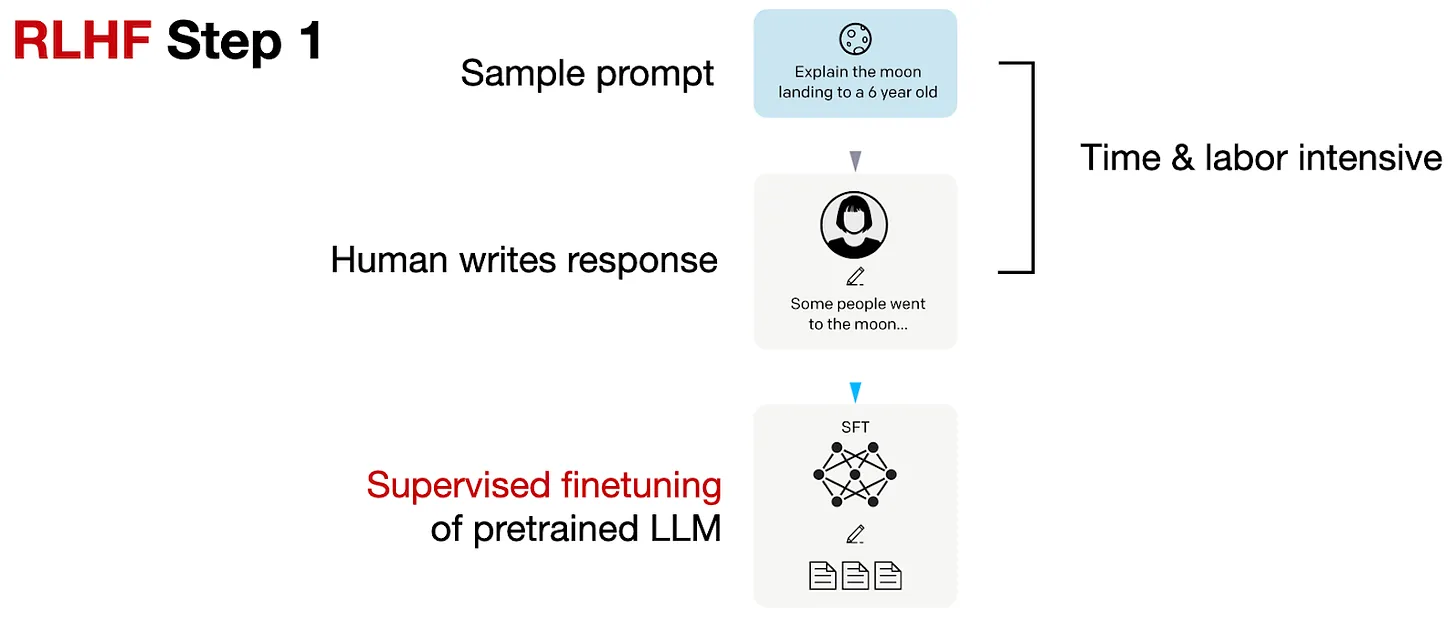
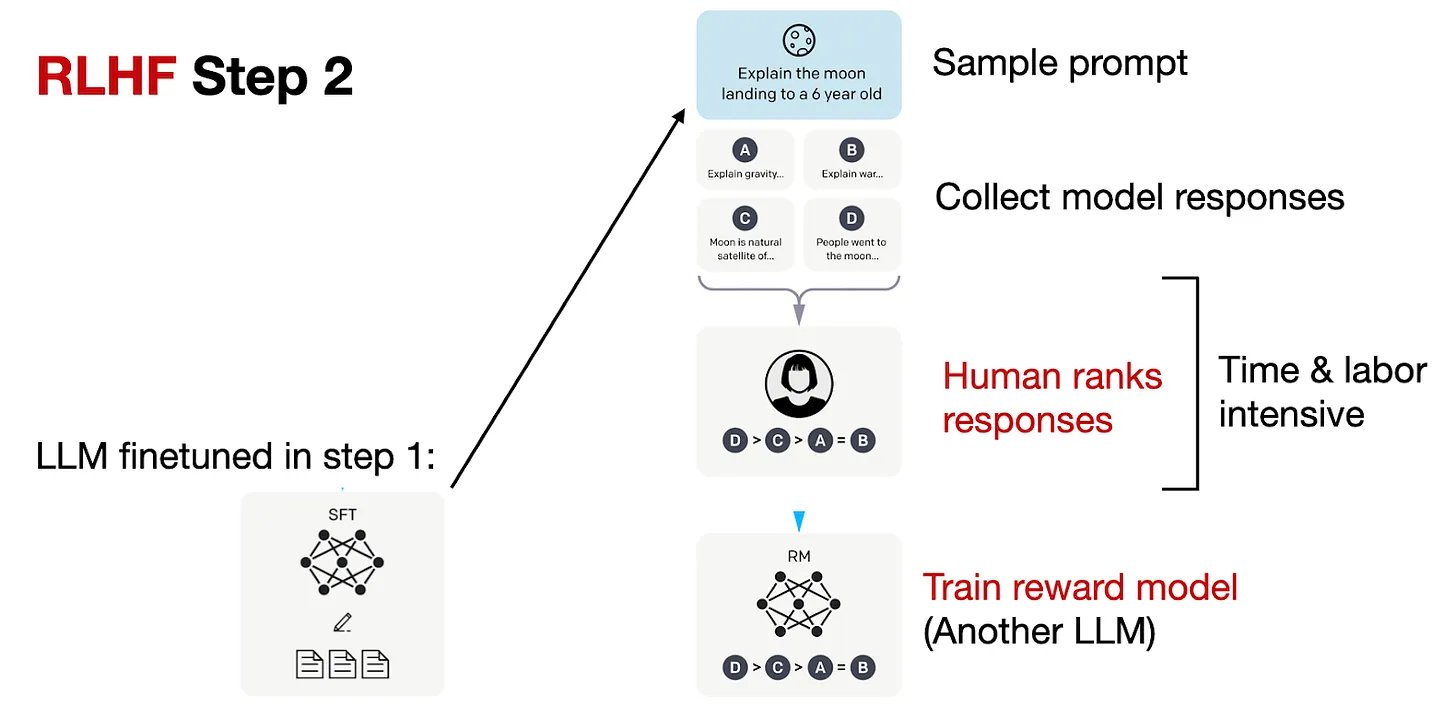
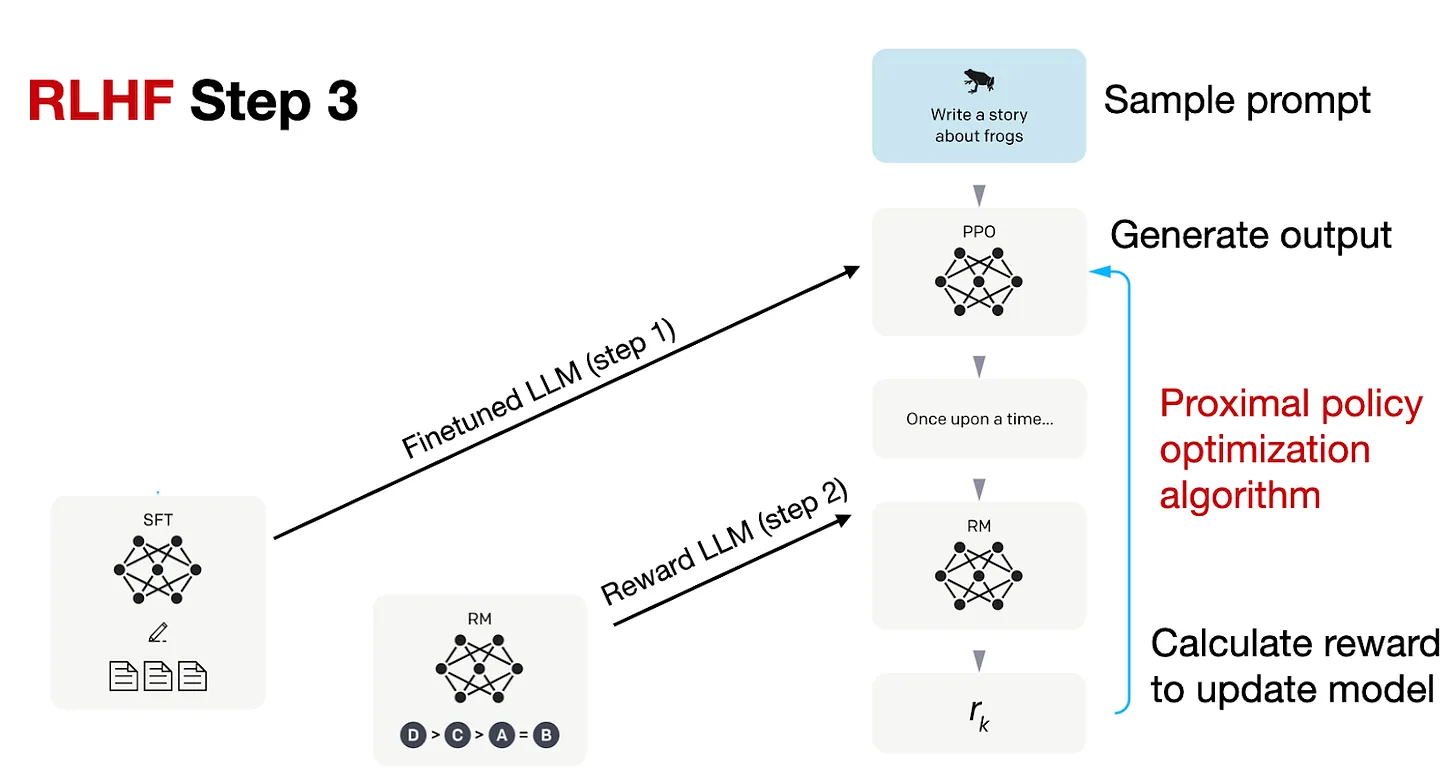
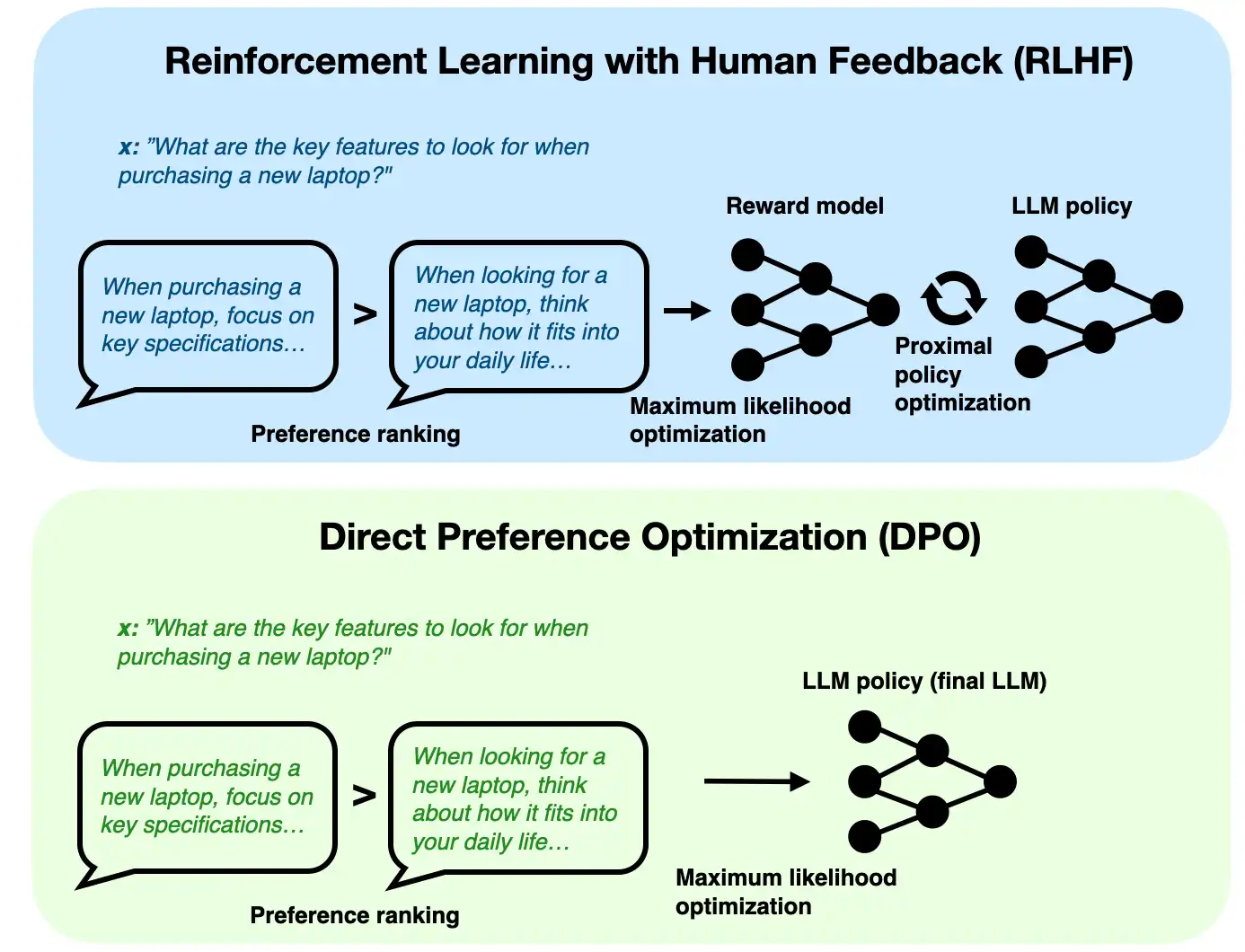
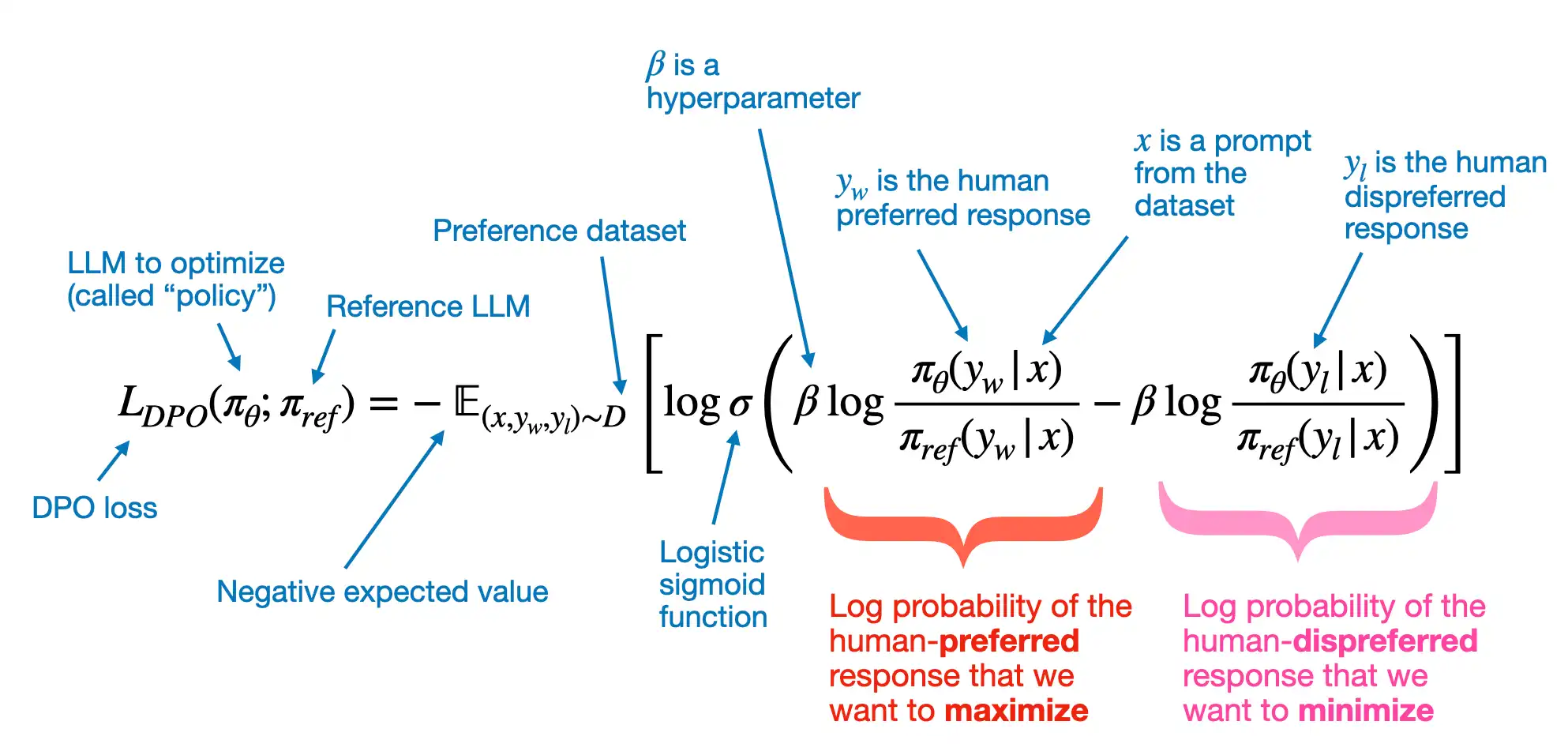

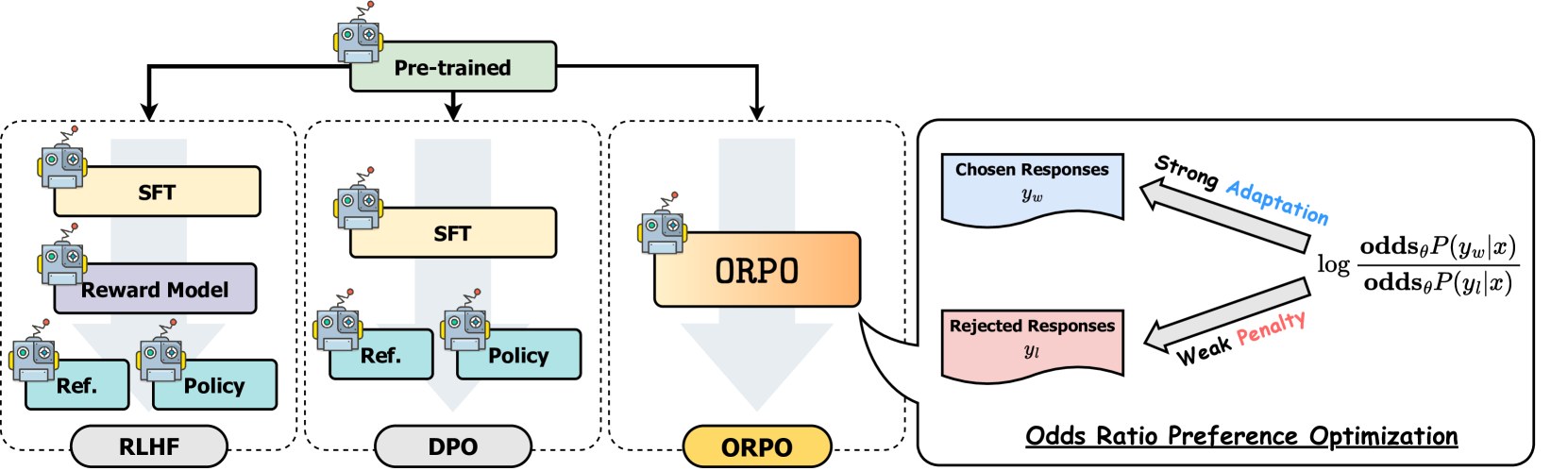
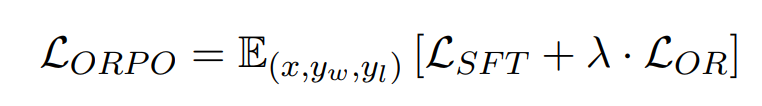
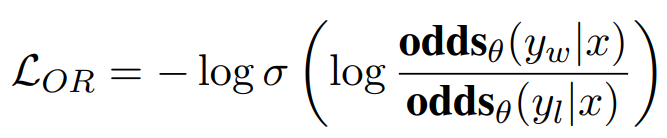
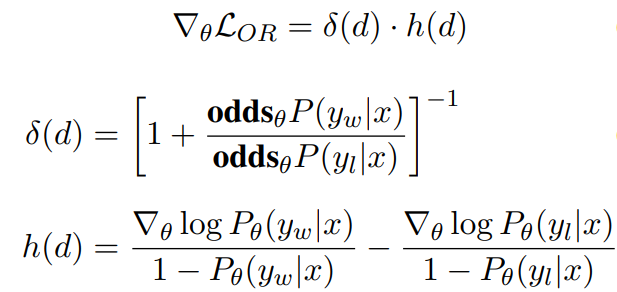
odds(p) = p/(1-p) -> prob of event happening / prob of not happening OR(a,b) = odds(a)/odds(b) yw -> desired response yl -> undesired response Aim OR(yw,yl) to be high
Lor -> is low if OR(yw,yl) is high and vice versa
Delta(Lor) = delta(d).h(d) Aim to decrease Delta(Lor) as yw increases, yl decreases and vice versa delta(d) -> odds(yl)/(odds(yw)+odds(yl)) –> decreases as yl decreases and yw increases h(d) -> increase as yw increases and decreases as yw decreases h(d) -> decreases (negative) as yl increases and increases as yl decreases
so gradient boosts yw increase and yl increase Implementation in HF library, probabilities we get are logsoftmax so applying exp will give actual probs.
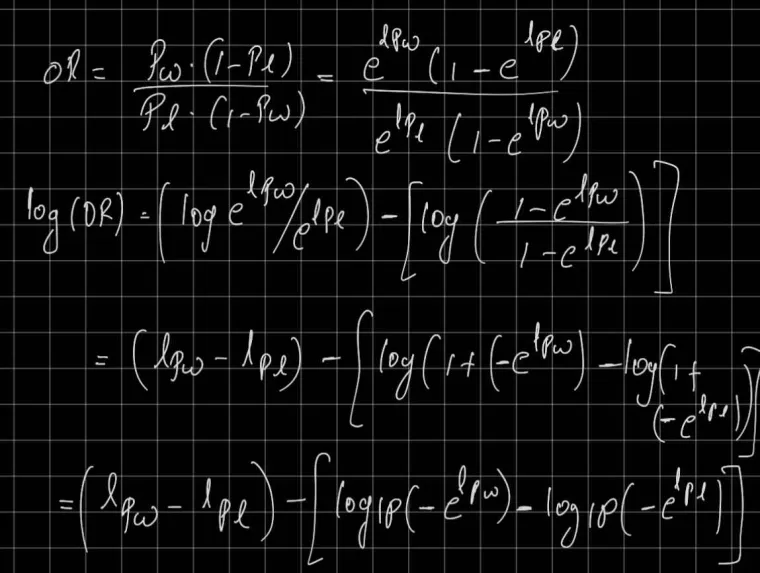
Latest Posts