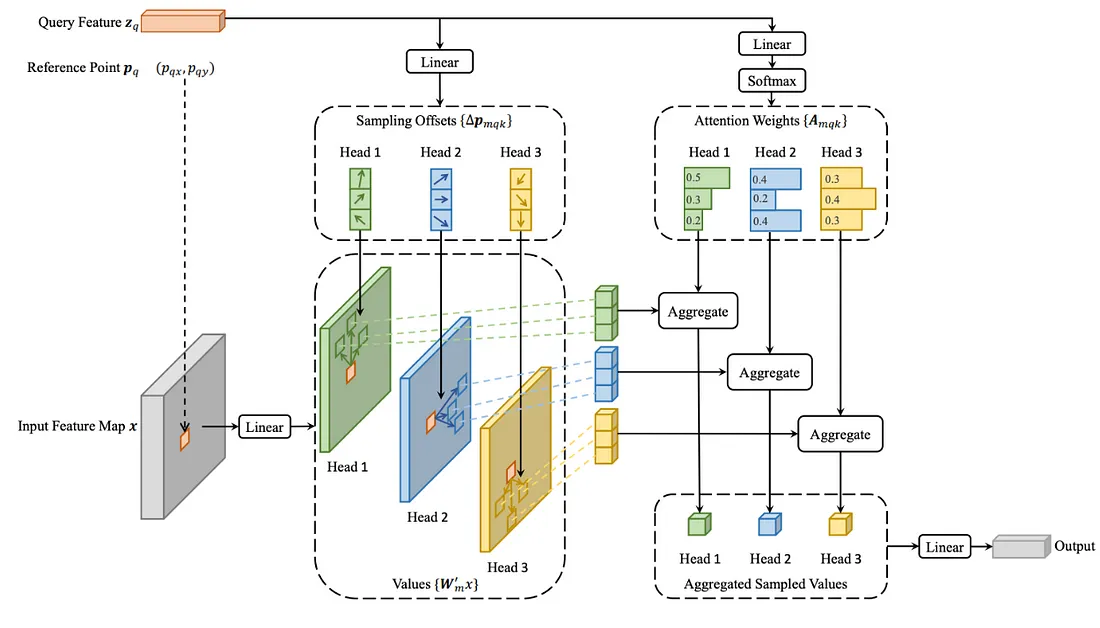
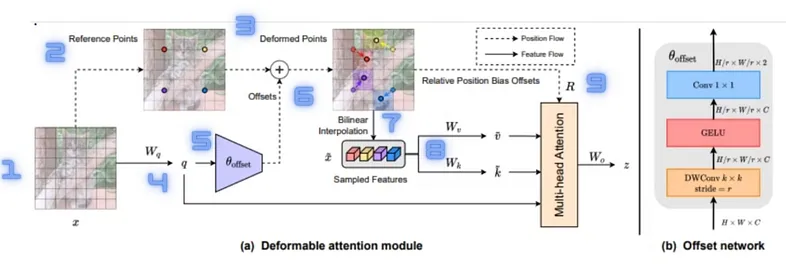
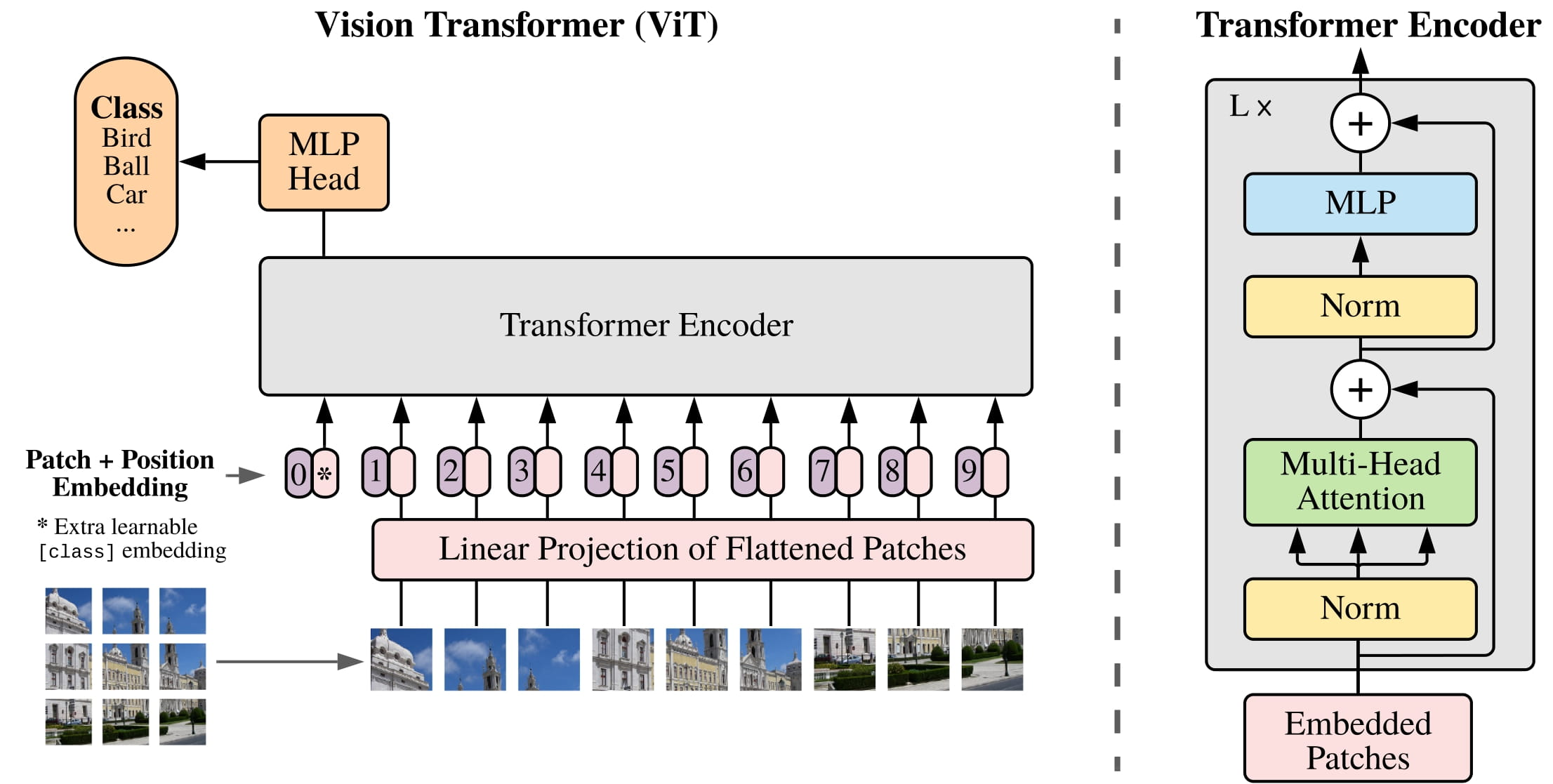
VIT
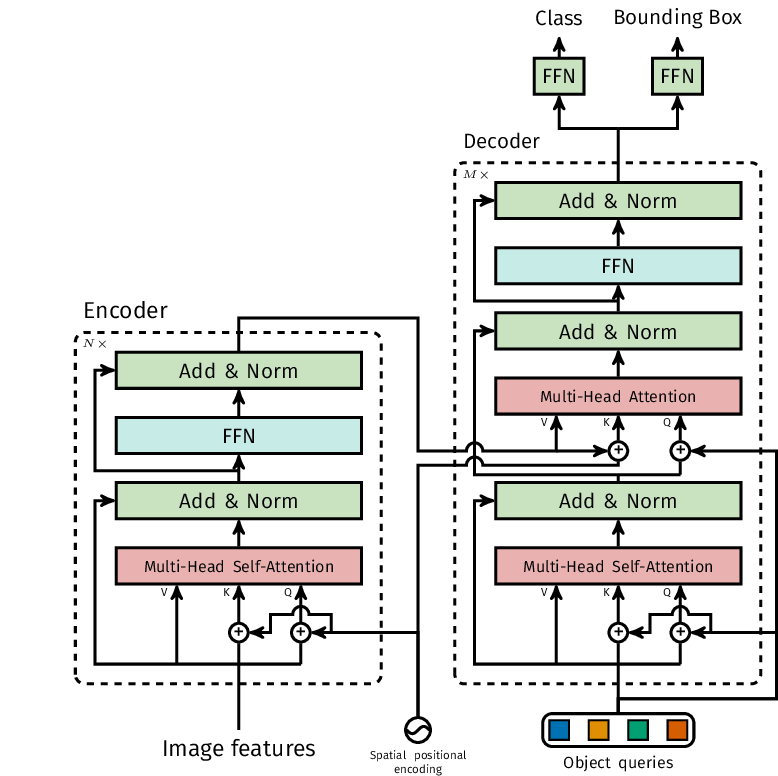
DETR
- Has fixed 100 object queries

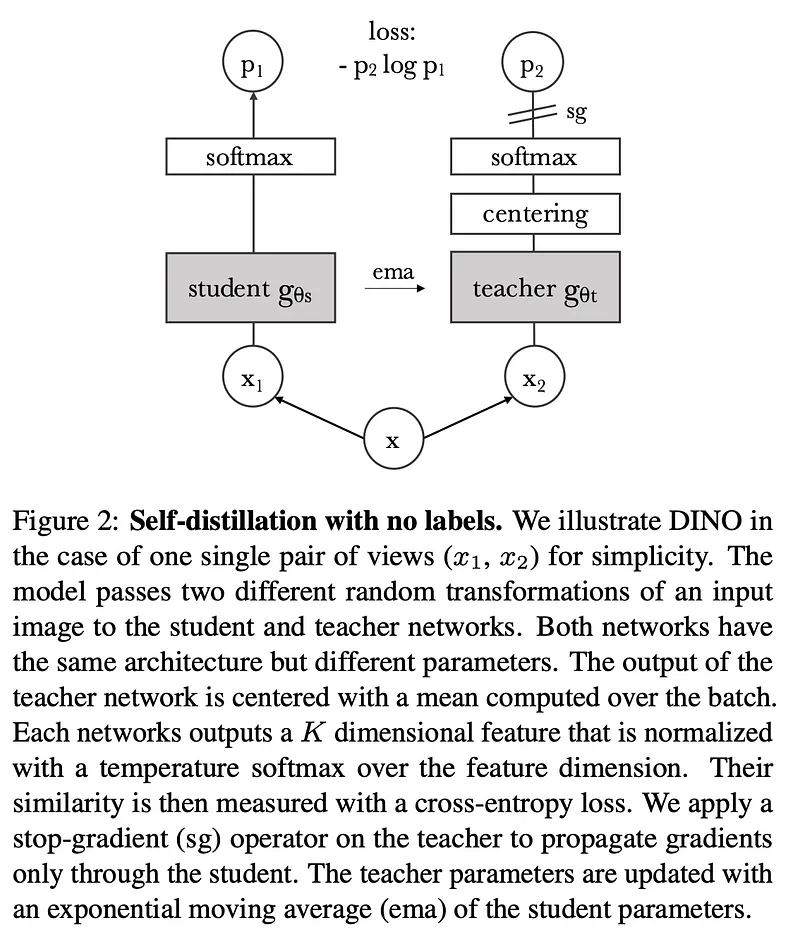
DINO
Emerging Properties in Self-Supervised Vision Transformers (DINO) — Paper Summary | by Anuj Dutt | Medium
Traditional Knowledge Distillation:
- Teacher Model: A pre-trained, larger model, usually frozen during training.
- Student Model: A smaller model, trained via back-propagation to mimic the teacher’s predictions.
- Objective: Transfer knowledge from the teacher’s weight distribution to the student.
- Model Diversity: Teacher and student can be different models, e.g., ResNet50 (Teacher) and SqueezeNet (Student).
- Loss Function: Typically uses KL Divergence loss on the output logits of both models.
SSL with DINO (DIstillation of NOisy labels)
DINO introduces a unique approach to knowledge distillation.
- Multi-crop Strategy: DINO generates various distorted views (crops) from an image, including two global views and several lower-resolution local views, using different augmentations.
- Local-to-Global Learning: All crops are passed through the student model, but only global views are processed by the teacher model. This teaches the student to relate local image patches with the global context from the teacher.
- Loss Minimization: The goal is to minimize a loss function measuring the similarity of representations from the student and teacher for different views of the same image, without using labeled data.